Searching Text in Natural Language Content
Users of the Web often want to search for specific text in a document or collection of documents without having to read line-by-line. Specifications sometimes seek to support this desire by exposing text searching in the Web platform.
There are different types of document searching. One type, called a full text search, is the sort of searching most often found in applications such as a search engine. This type of searching is complex, can be resource intensive, and often depends on processes outside the scope of a given search request.
A more limited form of text search (and the topic of this document) is sub-string matching
. One familiar form of sub-string matching is the find
feature of browsers and other types of user-agent. For user agents with physical keyboards, this functionality is often accessed via a key combination such as Cmd+F or Ctrl+F. Such a feature might be exposed on the Web via the API window.find, which is currently not fully standardized, or capabilities such as the proposed [[?SCROLL-TO-TEXT-FRAGMENT]].
Find operations can provide optional mechanisms for improving or tailoring the matching behavior. For example, the abilility to add (or remove) case sensitivity, whether the feature supports different aspects of a regular expression language such as wildcard characters, or whether to limit matches to whole words.
One way that sub-string matching usually differs from full-text search is that, while it might use various algorithms in an attempt to suppress or ignore textual variations, it usually does not produce matches that contain additional or unspecified character sequences, words, or phrases, such as would result from stemming or other NLP processes.
When attempting to standardize sub-string matching, specification authors often struggle with the complexity that is inherent in the encoding of natural language in computer systems, including the different mechanisms employed to encode characters in the [[Unicode]] standard.
Problems with Determining Equivalence
Quite often, the user's input doesn't consist of exactly the same sequence of code points as that used in the document being searched, while the user still expects a match to occur. This can happen for a variety of reasons. Sometimes it is because the text being searched varies in ways the user could not have predicted. In other cases it is because the user's keyboard or input method does not provide ready access to the textual variations needed. It can even be because the user cannot be bothered to input the text accurately.
In this section, we examine various common cases known to us which specification authors need to take into consideration when specifying a sub-string match API or mechanism.
Matching variation due to language
User expectations about whether their search term matches a given part of a document or [=corpus=] sometimes depends on the user's language, the language of the document, or both. It might also involve other factors, such as which keyboards or input methods are available on a given device. This might be because various operations that are part of searching, such as case folding, are locale-affected, or that, given the complexity of human language and culture, that expectations about matching or about the use and interpretation of various character sequences differs, even within a given script. Similarly, the handling of accents, alternate scripts, or character encoding (such as variations in the formation of grapheme clusters) is linked to the specific language of the text in question.
It is important to emphasize that we mean language here, and not script. Many different languages that share a script apply different processing or imply different expectations.
Implementations of a "find" feature often have to guess what language the user intended based solely on the user's input or on various "hints" in the runtime environment, such as the operating environment locale, the user agent's localization, or the language of the active keyboard. These hints are, at best, a proxy for the user's intent, particularly when the user is searching a document that doesn't match any of these or when the searched document contains more than one language.
Case Folding
A user might expect a term entered in lowercase to match uppercase equivalents (and perhaps vice-versa). Sub-string matching features, such as the browser "find" command, often offer a user-selectable option for matching (or not) the case of the input to that of the text.
For a survey of case folding, see the discussion here in [[CHARMOD-NORM]].
Unicode Normalization and character equivalence
Unicode defines canonical and compatibility relationships between characters which can impact user perceptions of string searching. For a detailed discussion of Unicode Normalization forms see Section 2.2 of [[CHARMOD-NORM]] as well as the definitions found in Unicode Normalization Forms [[UAX15]].
In many complex scripts it is possible to encode letters or vowel-signs in more than one way, but the alternatives are canonically equivalent.
Script Equivalence
Some languages are written in more than one script. A user searching a document might type in text in one script, but wish to find equivalent text in both scripts.
East Asian Width
Some compatibility characters were encoded into Unicode to account for single- or multibyte representation in legacy character encodings or for compatibility with certain layout behaviors in East Asian languages.
Ideographic Variation Sequences
The Chinese, Japanese, and Korean (CJK) writing systems sometimes encounter this issue.
A single [=ideograph=] can have multiple variants depending on the variation selector (VS) used. For example, 龍U+9F8D CJK UNIFIED IDEOGRAPH-9F8D when followed by different variation selectors, such as 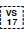
U+E0100 VARIATION SELECTOR-17 or 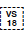
U+E0100 VARIATION SELECTOR-18, may represent distinct glyphs. String searching operations need to consider whether matches are performed on the ideograph alone or on the full Ideographic Variation Sequence (IVS).
When performing string searches, treat an [=IVS=] (e.g., 龍󠄀U+9F8D CJK UNIFIED IDEOGRAPH-9F8D + U+E0100 VARIATION SELECTOR-17) as a single unit and use the first code point as the processing baseline.
If possible, support both "fuzzy" and "precise" search modes to accommodate different user needs.
Digit Shaping
Many scripts have their own digit characters for the numbers from 0 to 9. In some Web applications, the familiar ASCII digits are replaced for display purposes with the local digit shapes. In other cases, the text actually might contain the Unicode characters for the local digits. Users attempting to search a document might expect that typing one form of digit will find the eqivalent digits.
Orthographic or Dialectical Variation
Some languages have different orthographic traditions that vary by region or dialect or allow different spellings of the same word. Searches and spell-checking may need to know about these variations.
South Asian (Indic script) languages
Indic script languages have many instances of this kind of problem. Sometimes these are spelling errors, but in other cases multiple spellings are acceptable.
For example, the Bengali language (language tag bn) is notorious for having a wide range of spelling variations permitted by the language: nearly 80% of Bengali words have at least two spellings. Many words have 3, 4, or more variations—with at least one word having 16 different valid spellings.
Other Indic scripts provide alternative mechanisms for representing particular sounds, and in most cases either representation is considered equally valid. The most common instance of this involves representation of syllable-final nasals.
For example, the /n/ sound in the word for snake in Hindi can be written using either ँ [U+0901 DEVANAGARI SIGN CANDRABINDU] and ं [U+0902 DEVANAGARI SIGN ANUSVARA] Both of the following are possible valid spellings:
In an additional twist to this story, two diacritics with different code points could be used here. In our previous example we used ं [U+0902 DEVANAGARI SIGN ANUSVARA ] to represent the nasal sound because the accompanying vowel-sign rises above the hanging baseline. If the vowel-sign was one that didn't rise above the hanging baseline, we would normally use ँ [U+0901 DEVANAGARI SIGN CANDRABINDU ] instead. The function of both of these diacritics is the same, but their code points are different.
The alternative use of either a letter or a diacritic for syllable-final nasals is common to several other Indian languages. In addition to Devanagari, used to write languages such as Hindi (language tag hi) or Marathi (language tag mr, scripts such as Malayalam, Gujarati, Odia, and others provide similar spelling options.
Whitespace Normalization
Some languages use whitespace to separate words, sentences, or paragraphs while others do not. When performing sub-string matching, different forms of whitespace found in [[Unicode]] must be normalized so that the match succeeds.
Accents and diacritic marks
Users will sometimes vary their input when dealing with letters that contain accents or diacritic marks when entering search terms in scripts (such as the Latin script) that use various diacritics, even though the text they are searching includes the additional marks. This is particularly true on mobile keyboards, where input of these characters can require additional effort. In these cases, users generally expect the search operation to be more "promiscuous" to make up for their failure to make the additional effort needed.
This effect might vary depending on context as well. For example, a person using a physical keyboard may have direct access to accented letters, while a virtual or on-screen keyboard may require extra effort to access and select the same letters.
Optional characters
In some orthographies it is necessary to match strings with different numbers of characters.
A prime example of this involves vowel diacritics in abjads. For example, some languages that use the Arabic and Hebrew scripts do not require (but optionally allow) the user to input short vowels. (For some other languages in these scripts, the inclusion of the short vowels is not optional.) The presence or absence of vowels in the text being input or searched might impede a match if the user doesn't enter or know to enter them.
Visually identical text that is not canonically equivalent
In some cases, visually similar or identical glyph patterns can be made from different sequences of code points. Sometimes this is intentional and variations can be removed via Unicode normalization. But there are other cases in which similar-appearing [= graphemes =] are not made the same by normalisation, and they are not semantically equivalent.
Some languages which use the Arabic script also have [= graphemes =] which can be encoded in more than one way. In some cases, these variations are handled by Unicode Normalization, but in other cases they are not considered equivalent by Unicode, even if they appear visually to be identical. Sometimes these variations are considered to be valid spelling variations. In other cases they are the result of user's mistaken perception.
Word boundaries and "whole word" matching
Some languages, such as English or Arabic, use spaces between words. Other languages, such as Chinese, Japanese, or Thai, do not. Some language use spaces to separate other text units, such as phrases. In those languages that do not use spaces between words, computing "whole word" matching often depends on the ability to determine word boundaries when the boundaries are not themselves encoded into the text.